ABOUT ME
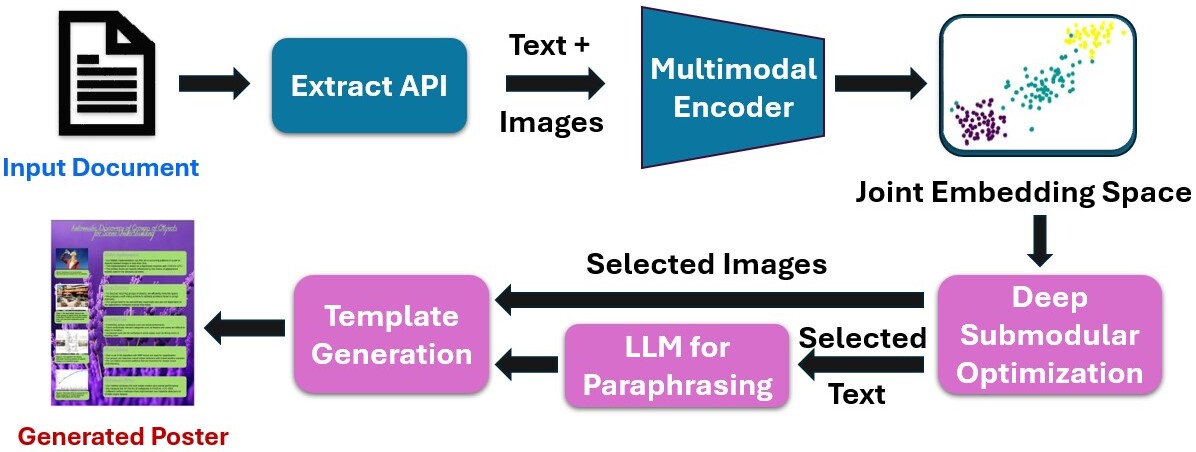
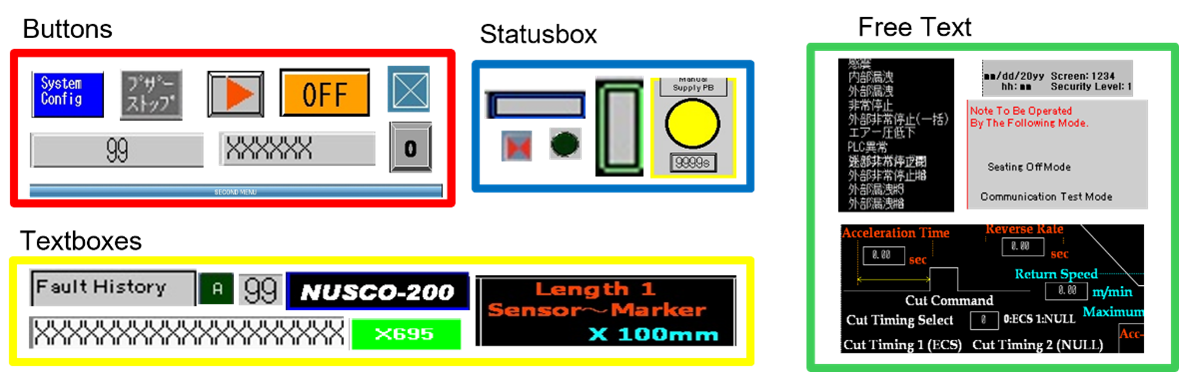
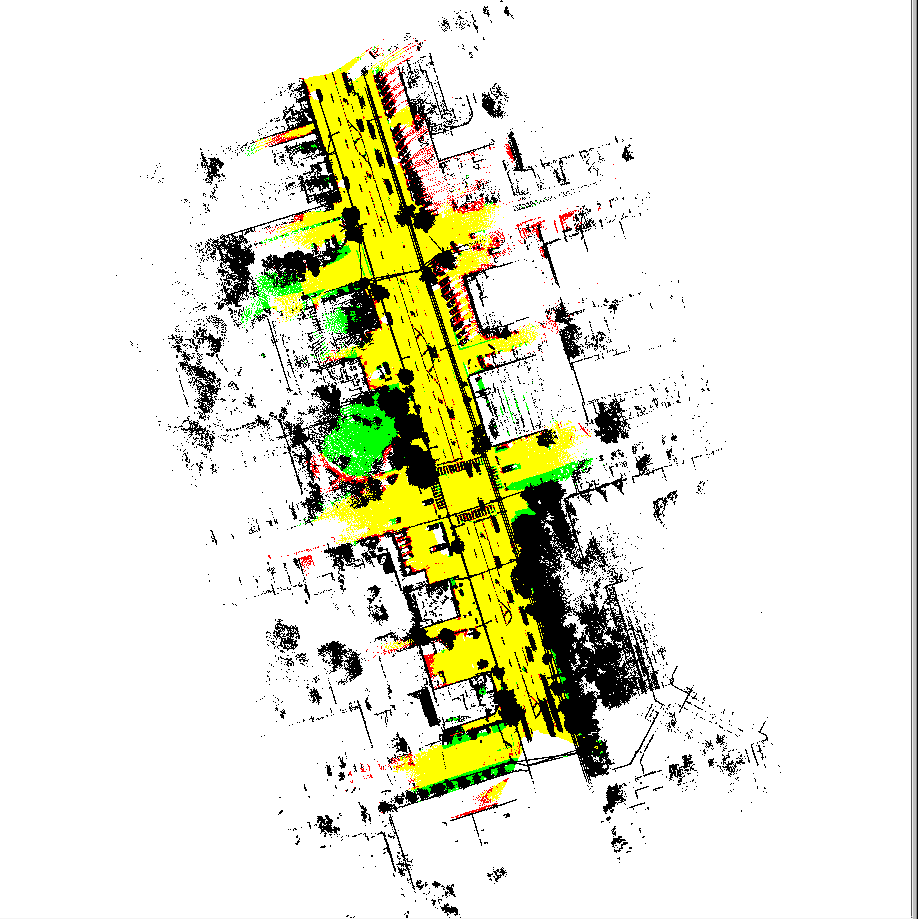
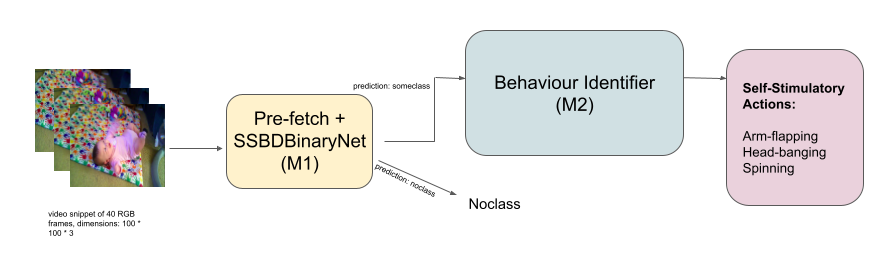
Presently, I work on integrating Computer Vision models into new energy offerings as a Senior Data Scientist at the Schneider Electric AI Hub and have a Master's degree in Computer Science from IIIT Bangalore. Previously, I was a summer intern at Adobe Research, working on poster generation from long multimodal documents.
My research interests are in the fields of Multimodal Learning, Adversarial Robustness, Explainability, and Computational Creativity. Computer Vision models can be game-changers in various disciplines like Health, the Creative industry, and Sustainability, and I wish to contribute towards exploring these models' innate capabilities and robustness towards real-world deployment conditions. Outside of work, I love participating in Hackathons, and playing tennis and table tennis.
I am interested in collaborating on new projects and challenges. Please feel free to contact me on Twitter, Linkedin or via email. Else, if you're in Bangalore, I'm always in for a meeting over Filter Coffee and Masala dosa 😊
I like looking at loss curves. Image generated using Stable Diffusion.